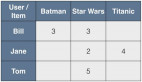
——近邻选择与算法拓展")
【51CTO.com原创稿件】
1.导读
通过上面几篇文稿可以详细了解到推荐算法的种类和优缺点,对于推荐算法这块内容还有很多,之前的几篇文稿在内容程度上多少有些许遗漏,以及之前阐述的算法内容深入程度上仍旧达不到一个专业推荐系统开发人员的水平。为此,在这篇文稿中,我将会对前面阐述的遗漏内容进行补充,并在之前的基础上提高一个层次,来在推荐系统算法中更加深入一步。
2.协同过滤算法(CF)拓展
2.1 相似度度量延伸
在之前的协同过滤算法中,阐述了在近邻推荐中运用到的相似度度量方法包括皮尔逊相关系数(Pearson Correlation)和改进余弦向量相似度(Adjuested Cosine)。皮尔逊相关系数在基于用户近邻推荐算法中常用的一种度量公式,它的推荐效果最佳。而改进余弦向量相似度是在基于物品近邻推荐算法中最常用的一个相似度度量计算公式,效果最佳。除此之外,还有一些不太常用的两种度量公式,因为它的推荐效果不是很好,因此在之前内容中就没有进行介绍了,在实际应用中也不推荐使用。但是有必要去了解下。
(1)均方差(Mean Squared Difference),它是使用用户u和用户v之间对相同物品评分差的平方和均值的倒数来表示两个人的相似度,然而有一个缺点就是不能表示负关联的关系。
(2)斯皮尔曼等级关联(Spearman Correlation),它是利用用户对物品评分的排名来计算两个用户之间的相似度。但是缺点就是计算排名时,消耗就比较大了,而且对于用户评分只有少量可选值的情况下,就会产生大量并列的排名,也就会造成推荐效果不佳。
2.2 两种特殊情况?
第一种情况就是在基于近邻推荐算法运用中,当两个用户对物品进行评分的时候,如果评分的商品比较少,并且对商品的评分的分数比较一致的情况下,我们自然就会认为这两个用户时比较相似的。在基于物品近邻推荐算法中也是一样的。但是其实在这个时候两个用户的爱好在事实上可能是完全不同的。因此为了解决这个问题,可以通过在相似度上添加一个重要性权重过着是进行一个相似度缩放的方式来对相似度进行转换。这样处理后的相似度才更能接近实际的用户相似情况。下面,就这重要性权威和相似度缩放这两个方式来进行延伸。
(1)重要性权重:对于两个用户或者物品之间的共同评分的物品和用户数量小于给定阈值的时候,那就降低相似度重要性的权重。阈值的选定一般是通过交叉验证的方法来进行的。实际场景中,一般当阈值大于或者等于25的时候,往往会收到比较好的预测效果。
(2)相似度缩放:给出一个收缩因子对用户或者物品相似度进行收缩转换时,当最后的共同评分数量远远大于收缩因子的时候,物品的相似度几乎没有变化;在实际场景中,当收缩因子为100的时候,得到的效果不错。
下面就是通过重要性权重和相似度缩放两种方式来计算的相似度公式:
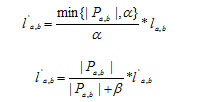
另外一种情况就是当两个用户对物品给出一致的喜欢和不喜欢的评分的时候,可能会不如他们给出差异更大的评分的时候提供的信息量多而有用。这个时候可以通过使用反用户频率(Inverse User Frequence)来对相似度计算公式进行转换,每个物品都会被赋以权重,权重的公式如下:
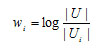
通过反用户频率对相似度计算公式进行转换时,所用到的皮尔逊相关系数也就变成了频率加权皮尔逊相关系数(Frequencey-Weighted Pearson Correlation),相应的公式如下:
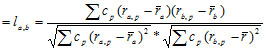
频率加权皮尔逊相关系数 2.3 近邻的选择问题?
之前的稿子中提到了协同过滤算法,它是通过选择当前用户的近邻用户群来完成对当前用户的推荐。可是不知道读者有没有想过,近邻的选择是凭空随便选的吗?难道没有近邻选择的方法吗?答案是有的。不过在之前没有进行深入,因为之前的相关知识点太多,很容易弄混淆。在这,就近邻的选择问题来阐述下:
在基于近邻进行推荐的算法中,近邻数量的选择以及对于近邻选择的规则都会对推荐系统的最终效果产生重要影响。在实际运用场景中,一般在基于近邻推荐算法中近邻的选择方式有以下方式:
(1)先过滤出预选近邻,过滤的方法有Top-N过滤、阈值过滤和负数过滤。这几个过滤通过名字基本就知道了过滤方法了。Top-N过滤无非就是选取排名靠前的N个物品或者用户;阈值过滤无非就是设置个参数,超过或者低于这个参数就会被过滤掉之类的;而负数过滤也就无非过滤掉负数这类的。
(2).在从预选的近邻列表中获取所设定的k个近邻;如果所选取的k的数目过小的话,就会导致预测精度非常低。当随着k的增大,预测精度就会有一定的提升,但是过犹不及,达到一定参数值的时候(一般在实际场景中是50),由于存在一些重要的关联被不重要的关联给削弱了,就会导致预测精度下降了,因此推荐k的选值为25至50之间。不过在实际运用场景中,最优的k值还得通过训练集和测试集来通过交叉验证来获取。k-近邻(KNN)具体的选取步骤即对未知类别属性的数据集的每个点依次执行以下操作:
(1)先计算已知类别数据集中的每个点与当前点之间的距离,
(2)按取距离递增次序排序;
(3)选取和当前点距离最近的k(预设定)个点;
(4)确定前k个点所在类别的出现频率,按照出现频率最高的k个点的类别来作为当前点的预测类别。
3. K-means算法
在协同过滤算法的SVD矩阵因子分解中,分解后的或者未分解的评分矩阵丰富度过高,也就是评分数量过多的话,会造成算法时间复杂度过高,对实时性造成严重影响。这时候就会采取之前所说的K-means算法,但是在之前的文稿中也只是随便提及了而已,并没有进行过多阐述。因此在这里对K-means算法进行介绍下。
K-mans算法的步骤和思想其实也比较容易理解,就是将数据集中的每一个点进行分类归整。将相同属性类别的点归为一类。算法接收端输入的是一个尚未标记的数据集,然后通过聚类算法对数据集的每个点分为不同的组,这也是一种无监督的学习算法。具体步骤大致分为以下几步:
(1)先随机地选取k个点(k的值先预设出来,一般选取小值比较好),来作为聚类的中心点;
(2)计算每个点分别到选取好的k个聚类中心点的距离,通过每个点如其他中心点的距离来进行排序,将该点划分给距离最近的那个聚类里面,依次分别划分所有点的类别;
(3)再重新计算每个聚类的中心点;
(4)不断重复以上2、3两步,直到聚类的中心点的位置不发生改变或者已经达到了之前预设的迭代次数为止。
4. SGD随机梯度下降
4.1 SGD含义
在之前的文稿中也提到了SGD随机梯度下降算法,这个算法一般用来不断调整参数来减小函数或者结果的损失及误差的。也就是给定一个损失函数,然后通过梯度下降的算法来使这个损失函数最小化。所谓的梯度下降的理解就是,首先对于每个函数图像曲面上都有各个方向上的导数,也就是函数在各个方向上的斜率。而曲面上各个方向导数中,最大导数值的方向也就代表了梯度的方向。因此梯度下降就是沿着梯度的反方向来进行权重的更新,从而有效的找到了全局的最优解。
4.2 小的理解案例?
这里提一个容易让别人理解SGD随机梯度下降的例子,就是将你放到一座山的任何一个地方,让你通过某一方法最快到达山顶或者山底。其实这个方法就可以利用SGD随机梯度下降方法。先找到各个方向的导数,也就是斜率,然后找到斜率或者导数最大的那个方向也就是梯度,沿着梯度方向走一步然后再计算梯度方向,依次类推不断行进。通过梯度下降方法可以让自己每一步都是处于当前位置趋势最大的方向,从而最快的下降到山底或者上升到山顶。通过这个原理也就可以以最快的速度来降低损失函数值或者误差。
5.推荐系统扩展——攻击
在实际应用中,因为推荐系统的建议或多或少会影响用户的购买行为,因此在带来经济效益的同时,不能假设所有参与评分建议的用户都是诚实公平的。也就是说,林子大了,什么鸟类都有。在众多提供推荐建议或者评分建议的用户中。肯定是存在一部分恶意用户的,他们会影响到推荐系统的推荐效果,以至于让推荐系统中的最终推荐列表经常或者很少包含某类的商品,这种问题就叫推荐系统攻击了。当然对于这种推荐攻击情况,所有推荐系统都会遇到的,也有一些相应的解决办法:
(1)尽可能的提高那些稳定或者可信度高的用户的评分权重,也就是一些长期购买的或者会员用户等;
(2)过滤掉异常的数据,比如前后评分差异悬殊的数据,因为当有大量的异常数据存在时,才会对推荐结果造成不好的影响。
6.推荐系统的实现
6.1 推荐系统实现意义
对于任何一个推荐系统的开发人员来讲,谈再多理论知识只是一个基础,关联重点在于实际用代码去实现一个推荐系统。毕竟理论来源于实践,只有自己真正设计好一个推荐系统或者完成一个推荐功能后,才能够真正把握之前的推荐系统理论知识。将理论知识进一步升华,过渡到实际运用中去,这也是任何一家公司对一个程序员基本的代码能力要求。
对于完成设计一个推荐系统或者完成一个推荐功能模拟,有很多方法或者框架都可以用。运用框架可以有利于开发人员快速的去生成一个推荐功能模块,在整体上更好地把握到自己设计的推荐系统功能。而且,在目前开发的行情来看,框架是绝大多数开发人员的必选条件之一。因为达到只有开发领域的技术专家程度,才能从真正意义上脱离框架,不过也;没有必要脱离,因为运用框架也是“站在巨人的肩膀上”,前辈们的经验或者技巧完全可以去运用学习的。
6.2 框架分类
推荐系统所用到的框架中,比较通用的主要分为两大类,一类是在学术界科研领域运用广泛,另外一种就是在企业开发领域常用的了。学术界运用广泛的主要有LibMF、SVDFeature等,企业开发一般会用到Mahout、SparmMLib、Waffles等。
而且在开发语言上的选取也有所不同,学术界一般更加重视理论性和发展性,采用的语言更加倾向于C、C++以及Python,而企业开发更加会重视语言的流行度后效率,因而更偏爱JAVA、scala或者Python。由此可见,Python语言在这一块领域会更加吃香些。因此站在很多高校都新开了必修课就是Python语言的学习,企业也对会使用Python的学生和员工更加青睐。目前的发展势头很猛,有很多人都说有可能会追赶上开发语言流行度冠军——JAVA,拿下榜首的位置,虽然现在还没有实现。为此,在这一系列结束后,我会在后面开一个Python语言进阶的系列,在掌握Python的基础上,再去实现一个推荐系统会更加游刃有余。
7.总结
至此,推荐算法集锦这块的理论知识系列已经完全结束了,后面先通过Python技术的了解与掌握后,然后再对推荐系统或者推荐功能的设计来完成实战性的模拟演练。这一系列的推荐算法内容比较繁多,广大读者只有在理解这些内容的基础上,才能够继续对推荐这块有一个更好的延伸拓展。而且对于推荐系统的设计,这条道路始终是没有尽头的,是需要精益求精的。为配合时代的发展,推荐系统也越来越倾向于结合火热的人工智能领域来进一步加强推荐的效果及稳定性,因此推荐系统邂逅深度学习势不可挡,也是未来推荐系统能完成新的突破或蜕变的方向所在。希望在未来,深度学习技术真的能作为推荐系统的两双翅膀,来让推荐系统继续腾飞一次。因此,对于深度学习或者人工智能领域这块的学习也是必不可少的,今后我也会就深度学习方面的知识来简要概述下,来为读者打下一个深度学习技术方面的基础。
【51CTO原创稿件,合作站点转载请注明原文作者和出处为51CTO.com】