很多时候,所谓的架构演进没有太多的前瞻,大部分都是被逼出来的。
什么时候还技术债、变革或者跟上一些潮流趋势,很多公司是根据业务来判断的,而我们则是分三个阶段:
- 冒烟
- 小火
- 大火
我们能够做到的是尽可能在冒烟阶段做一些技术的变革,如果出小火的时候再做技术的改革,那就有点晚了;到大火的话,相当于被逼的没有办法了。
尽管是在同一个行业,不同的公司会有一些差别,我对美团也略有了解,我们在技术上还是略微有一些差别。
我今天的分享分为以下四个部分:
- 挑战(challenge)。有些技术是普适的、通用的,比如我们一直在用的 TiDB,再比如 Office 一类的软件,但我们并不是将解决方案(solution)卖给谁。
有一些欧洲和美国的朋友找到我,说我们在那边 copy 一套是不是就能 work,这是不现实的。我们现在值钱的不是代码,而是一批对业务了解的人,能把业务跑起来,所以我们与通用技术的差异是比较大的。
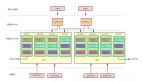
- 架构(architecture)。architecture 里有一张图是家家都有的,大同小异。但为什么我们到今天折腾成这样一张图,而不是在三年前?因为这里面有很多现实的困难。
- 拓扑和数据(topology & data)。这里会有带说明的拓扑以及一些数据。数据其实有很多辛酸在里面,也出过很多宕机,线上业务最怕的就是宕机。
- 正在做的以及未来计划(doing & planning)。这里是有点精神追求的,我们现在处于冒烟的阶段。
饿了么的技术挑战
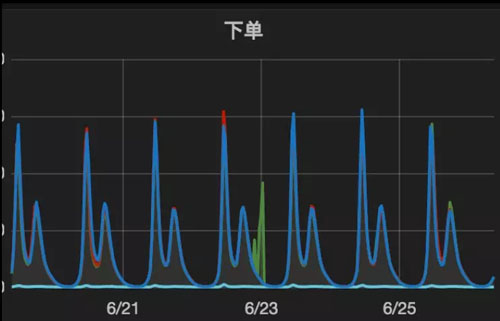
如上图,是下单量随时间变化的曲线图,这就是外卖行业的特色,绿色部分表示一些异常。前端流量会更大一些,因为两者有一个转化。
电商在国内有这样的曲线,应该只有外卖这个行业,我们二家(饿了么和美团)都差不多。
在业务上要“削峰填谷”是很难的,因为我们做那么多年的努力才培养出来这样的习惯,但是在技术上要想办法。
看到这张图大家会不会想,你们这家公司不搞云计算,就存在机器超级严重的浪费。
我想告诉大家,就是非常严重的浪费,但是没有办法,我现在做的容量规划就是基于波峰来做。
我们也想给公司节省成本,IT 部门投入蛮大,公司也不会削减预算。我们现在很在意成本,因此在考虑怎么给公司减负。

今天主要讲云、后端的冲击、在“削峰填谷”上面我们要做什么事情以及为什么要做混合云。
作为程序员,我最喜欢的就是简单,能用钱砸的就不要安排一堆人去做。但是现在混合云越来越复杂,还要做很多调度器之间的适配。
比如 YARN 怎么跟 ZStack、Mesos 适配?我们是重度的 Mesos 用户,做了大量的二次开发,适配是非常麻烦的。
对于高并发或者秒杀的冲击还好,但是最大的是成本问题:怎么提升单位运营的效率?公司拼到最后,活下来就是拼效率,不是拼谁钱多。一切围绕着效率来走,在这个出发点下我们做了一些架构的改造。
我们原来做灾备,相对容易些,但后来灾备也做不下去了。这不光是一个排除法,之前踩的坑对你做下一个选项是有价值的。
饿了么的架构演进
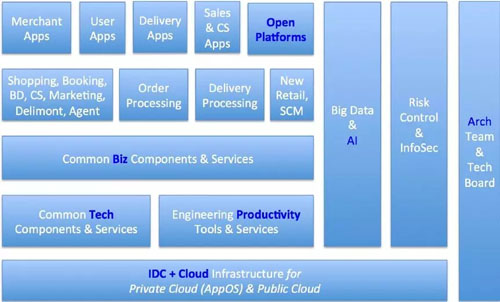
5 年前我们没有这张图,还处于人肉运维阶段,那时才叫 DevOps(a software engineering culture and practice that aims at unifying software development (Dev) and software operation (Ops))。
为什么呢?因为我们的工程师就是 Ops,没有专门的 Ops 团队。三年前我进去后发现很夸张,团队就一个专职 DBA(Database administration)和一个 Ops。
后来我发现不行,要招人,我招人完全超出你的想象,是招一堆人写业务逻辑。业务逻辑没有办法智能,也没有办法像刘奇他们招三个中国最顶尖的程序员就可以搞定。
对业务逻辑是这样的,我们已经抽象了,但是还是不行,业务逻辑 AI 解决不了,后来发现招人不行,做的项目乱七八糟的,系统也老挂。
我也不是吐槽 Pyhton,我们最近也做了大计划,大概会省几亿的人民币,就是 Python 转 Go,因为大部分流量靠 Python 扛的,集群压力也是蛮大的。用 Go 的话(成本)大概除以 5。
今天讲 IDC(Internet data center)+ Cloud,因为我们自己有 IDC,总不能报废吧?
虽然机器三年折旧,但我们每年还会有一些增量补上去,而且我们还有一个很大的运维团队。
这时,Cloud 又复杂了。我们基本上把国内四大云都用遍了,我们原来是腾讯云和百度云第一大用户,阿里云不是第一估计也是前三,然后还有七牛云,总之我们把四大云都裹在里面。
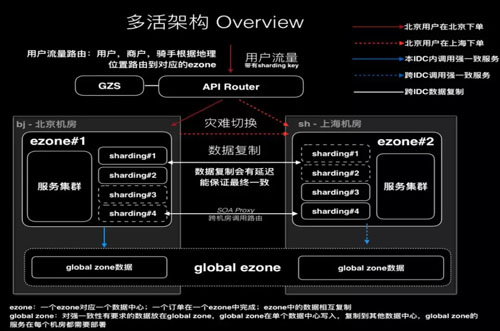
最早我们想做灾备,但灾备有一个很大的麻烦,就是真到灾难的时候不敢切换。
我们当时做的灾备不顺利,最大的开销不在部署而是在测试,因为灾备是没有生产流量的,验证起来很困难。
业务逻辑还好,比如多了个接口,少了个应用,从异步变为同步,但也很令人崩溃。
这一堆的事情最后让我们暂停了项目,这个项目(灾备)是我发起的,也是我叫停的。这是个赌局,包括 Google、TiDB 是不可能保证 100% 可靠的,总有一定的概率,无非是几个 9的问题。
我们的(多活架构)coding & deploy & 测试加起来就三个月,前期准备了 9 个月。好多团队异地多活很容易,三个月就可以搞定,其实不然。
首先,异地多活不是一个技术活,要想清楚业务需不需要。我们是被业务逼得没办法,因为灾备没有搞好,现在觉得灾备也确实不好搞。 所以在偏业务的公司搞技术是一件很麻烦的事情。
这里讲一下 global zone。我们有两种 transaction,一个是下单,一个是配送。
大部分 transaction 都可以在一个机房完成,但还有一些东西是绕不过去的,需要用到 global zong。
百度也做了多活,叫“同城多活”,严格意义上那不是多活,“同城”就类似于 global zone。
要是仅仅安于北京和上海,其实 BGP 放哪里都无所谓,但如果要打两百个城市,在一些三四线城市,你根本没有办法。
因为我们是 IDC 不是云,云你是无所谓在哪里的。我们的异地多活是被迫的,我很喜欢百度的“同城伪多活”。
百度外卖用的百度云,在广州有两个机房,延迟大概 2ms。只有一个地方有 master ,流量是均分的。如果流量跟 master 的 DB 不在一起,就会通过专线同城穿一下,这就相当于我们的 global zone。
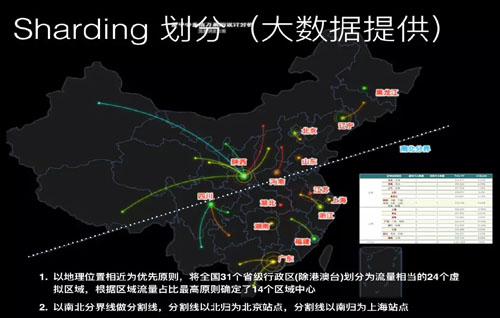
如上图,这是典型的南北线,但也不是南北的线,是根据流量切分的。

如上图,我们有 4 个调度器,非常的头疼。我们讲一下 ZStack,在 Docker 没推之前,基本都是在 ZStack 上,也就是虚拟机,物理机没有特别的调度。
我们大概有 20% 的节点部署了 Docker,有多公司已经 100% 使用 Docker,但我们现在做不到,有一些现实的困难。
Docker 化也有一点麻烦,有些集群是没法迁 Docker 的,比如 ElasticSearch 这种有状态的服务。我们现在也开始自研分布式存储系统,从 EMC 挖人来做,但还处于冒烟阶段。
再来说说大数据的 TP(Transaction Processing)和 AP(Analytical Processing)。
我们的 AP 原来基本上都在 YARN 上面。大家可能会诧异,我们现在这样的一个情况,为什么不是 Kubernetes?
这也是被逼的,开始就没有打算用 Kubernetes,而是用 Mesos。很多时候跟你的团队有关,团队在 Mesos 上面已经很长时间了,业务也比较稳定,而Kubernetes 太复杂,上手也比较重。
现在上 Kubernetes 是因为要用 Google 的产品,我们现在有一个机器学习平台,除了 Spark,也有机器学习。但还有一些同学,特别是用惯 Python 的,用惯 Tenserflow 的,我们现在都走 elearn(自研AI over Kubernetes)。
大家会感觉很诧异,我们居然不是在 TP 上部署 Kubernetes,我们 TP 上现在主要是 Mesos 和 ZStack。
这时,Cloud 更麻烦了,现在饿了么这边主要还是阿里云,百度外卖那边主要是百度云。
百度云也有很头疼的问题,前两天跟他们聊,也是很痛苦的。我们的团队坚持要用物理机的,原来在腾讯云上面的时候,我们就有自己有物理机,并且挪到了腾讯云的机房。
但现在阿里云不能让我们把自己的机器给挪进去的。怎么办呢?在今年云栖上已经提到了,我们算是第一批用的。我们要坚持用物理机,否则 IO 密集的任务根本跑不起来。
RDS(Relational Database Service)我们也试过,但只是用在测试。我们所有的程序员和 QA(Quality Assurance)用的环境都是在阿里云上面,是用 RDS。
当然还有重要的原因,那就是 RDS 太贵了。我们也会在 Cloud 上部署二次开发的 Mesos。
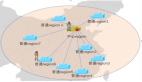
饿了么架构拓扑和大数据
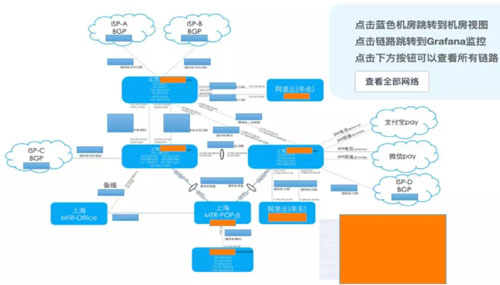
如上图所示,黄框基本上都是机房,包括 IDC 和 Cloud。最麻烦的就是北京和上海。
在我们上海新机房没有启用之前,大数据的 AP 和 TP 是混合部署的,但这个混部是隔开的,并不是真正意义上在一个 node 混部。
这边是阿里云华东和阿里云华北,腾讯云快下完了。另外还有一些专线,也就是两个支付(微信和支付宝)。
原来两个支付是不走专线的,后来发现走公网很难忍受,峰值的时候稍有抖动就受不了,一秒钟可能 1 万个订单就没了。
在支付这个环节丢掉客人是最伤的,如果 APP 一开始打不开就认了,但是什么流程都走完了,最后支付不成功,就很麻烦。
我们专线非常多,每条线都是一个环路。现在广州百度那边,百度云不是一个大的 IDC 架构,那边是完整的体系,到上海两个机房要做两条专线,每一条都是环路,也很复杂。
我们内部最头疼的不是 IDC,而是各种专线,因为非常复杂。还有到我们的 Office,还要有 POP 点。
我也不想搞的那么复杂,可能大家会说把北京的 IDC 废弃不就结了,但是没这么简单。因为前提是要搞多活,不管是异地还是同城。

我们现在北京和上海两个团队加在一起大概 25k 个节点。Docker 率只有不到 20%,我们的目标是 50%~60%,因为有很多是做不了的,尤其是中间件,用 Docker 不划算。
大数据这块当时狠了下心,把 TP 的应用全部“干掉”,但现在发现,虽然机房是以大数据为主了,但是 AP 和 TP 同城能不能合在一起,好不容易分开现在又要合在一起。
现在大数据的机房压力也比较大了,我们业务的增加是 120TB,除了大数据还有我们自己的系统日志、trace 差不多 400TB。每天要处理 3PB,总的存量是 12PB,数据量特别大。
我们现在的系统不能出问题,也不能停,尤其是通用软件的供应商。
不管这个客户是秒杀类的还是常规类的业务,肯定会受不了。我们还只是为自己的业务提供服务,损失要稍微小一些。
但是做公共设施,比如七牛云、TiDB,一旦停顿,所有的用户都找你麻烦,所以我们相对来说压力还算小。
我们业务没有办法,逼着我们每天发布 350 次,现在可能不止了,因为现在有很多新业务,每天发布好几次。
我们大数据非常的烧钱,最贵的 3 个集群:MySQL、Hadoop+Spark 还有 Redis。
Redis 还有很大的省钱空间,从经济/效率的角度来看,这个东西放在那儿很浪费。
还有大数据的备份,大数据是我们的命脉。如果网站宕一天,我们道歉一下就行了,第二天该来的用户还得来。
但大数据一旦出问题,一是数据是隐私,二是数据丢掉或者错乱,会更加麻烦。
我们每天做了很多的备份,但后来发现这些备份太冷了,到底划不划算,你不能去赌它,但是成本放那儿太痛苦了。混合云架构是被逼出来的,不是我想搞这些东西的。
饿了么正在做的以及未来计划
混合云架构

多活的难点主要在异地多活,同城伪多活是比较容易的,也就是 global zone 这种方式,但同城做真正的多活也跟异地差不多,主要是 latency 的问题。
你要自己做 DRC(Data Replication Center),包括 MySQL 层面,Zookeeper 层面和 Reids 层面。
我们用一个服务,就希望它是跨 IDC 的,主要就是 latency 和一致性,这两个问题很难协调。
还有 Cloud Native,是大势所趋,就像 Go 语言。冒烟时开始做,太超前了也不行,毕竟要先把业务做起来。
但是到小火就比较危险了,我们也曾到小火的时候再去还债,还债还算容易,到小火的时候真的靠人肉上去砸就比较麻烦了。
Cloud 肯定会考虑的,混合云虽然听上去很时尚,但是我们的步调比较谨慎。对运维团队也是个挑战,比如 RDS。
我们内部数据库也千奇百怪,有 MySQL、MongoDB。你让习惯了敲命令行,写脚本的运维变成程序员,我们内部反过来叫 OpsDev,这个难度要远超过 DevOps。我们希望公司所有人都是程序员,但是这个挑战蛮大的。
我们 Serverless 是在线上做了一个系统,但是比较简单。接下来可能会考虑短信推送,移动推送,因为这个只要搭个 Redis,开启就可以直接发送了。
对我们来说,Serverless 对复杂业务是走不通的,除非我们全部用 Cloud infrastructure。
Auto scaling 是我们在计划做的,因为多活做了之后才能相对宽松一些,流量想切多少切多少。
95% 的 transaction 都在同一个 zone 里做完的。不做这件事情就没有办法做阿里云的拓展。阿里云现在可以做 Auto scaling,但是成本很高。
一般来说,云的成本会比 IDC 要高一些,那是不是做 4 小时的拉起再拉出(值应对峰值流量)是划算的?
我们算了一笔账,发现不一定是这样。如果削峰填谷做的比较有成效的话,就会冲淡 Auto scaling 节省的成本。
我们和新浪微博不一样,它是不可预知突发事件的,所以只能做 on demand(按需)。虽然我们有很大的波谷差异,但是可以预知的。
前两天团队给我一个“炸弹”:我们现在机器利用率很低,我们不是上了 Docker 嘛,我们做一件事情——超卖。
什么叫超卖?我们原来是一核对一核,现在一核当两核,后来发现还不错,用 Docker 的人感觉没有什么变化。
我们继续超卖,一核当三核用,我们按峰值来算的,发现平时的峰值利用率也不是那么高。
混部尝试

不管我们要不要做 auto scaling,不管我们业务上要不要削峰填谷,都要做混部。
混部这块,百度走的早一些,他们前几年做了一个系统,目的不是要混部,但是要产生一个好的副作用来实现这样的功能。
回到业务本身,混部其实很难的,我跟他们聊的时候,说搜索这种业务是可以采用类似于网格计算的,每个格子自己算,然后汇聚。
他们有大量的 swap(数据交换),但你让 Spark 来做这些功能,比如 Machine Learning 和 swap,即使是万兆网卡,也会突然把带宽占满。
现在机器学习跟搜索或者爬虫可以分而治之的技术不一样,我们叫分布式,有大量的 swap。我们也在尝试,把能够在每一个节点单独计算,不需要大量 swap 的任务放上去。
混部是为了解决什么问题呢?我们业务的峰值非常高,到波谷的时候这些机器就闲置着,那是不是可以来跑一些 job。
这个 job 不是指 TP。TP 也有一些 job,但都耗不了多少 CPU。这是不划算的,不能纯粹玩技术,为了玩而玩,我们要解决的是大量的场景。
我们能想到的是 Hadoop、Spark,尤其是现在 Machine Learning 压力比较大。但是聊下来比较难,第一不能异地,第二同城也很难。
还有很头疼的挑战:我们大数据团队用的机型是定制的,他们已经习惯了这种机型模板。
我们 TP 的模板非常多,已经从上百种压缩到十几种,但还是量很大的,有 API 的,有业务逻辑的,有 Redis 的。如何把大数据或者 Machine Learning 的任务适配到杂七杂八的机型是个问题。
我们这个行业经常有促销活动。活动的时候即使有云,也还是要花钱的。所以活动期间可以把大数据任务冻结,释放机器资源用于大促。
大部分任务拖延三四个小时都是可以接受的。两边互相的部,首先解决资源隔离的问题,还有调度器。YARN 是很难调度 TP 的,Mesos 或者 Kubernetes 调度 AP 也是有麻烦的。
我们在研究的问题是 YARN、Mesos 和 ZStack 怎么适配,现在仍然没有搞定。
混部的问题早就存在,但是财务上面给我的压力没有到冒烟,如果饿了么哪天提供了饿了么云,大家不要惊讶。
我们不会去做公有云,但是曾经考虑介于 PaaS(Platform-as-a-Service)和 SaaS(Software-as-a-Service)之间的物流云。
我们现在有很多的配送并不来自于饿了么,也帮双 11 配送。现在也有叫闪送,可以在很短的时间送到,一个人送一个件,但是收费比较高。
我看到闪送的人直接骑摩托车送的,一般是电动车。很多时候业务发展起来了,正好也帮我们解决了这样的一些问题。