相信最近科技圈都在调侃一件事:10 月 8 日中午的一条微博,引发了一场新浪微博用户们(尤其是女性用户)之间的轩然大波,导致新浪微博瘫痪。
本文主要涉及知识点包括新浪微博爬虫、Python 对数据库的简单读写、简单的列表数据去重和自然语言处理(snowNLP 模块、机器学习)。适合有一定编程基础,并对 Python 有所了解的盆友阅读。
这条微博的始作俑者,就是全球超人气偶像明星鹿晗。
程序员们纷纷开启了科♂学地讨论:
详细内容可见昨日的图文:鹿晗是如何将微博服务器搞炸的?

微博工程师是如何一边结婚一边加班的:
淘宝程序员是如何原谅鹿晗的:
在这一刻,全世界都知道鹿晗恋爱了:
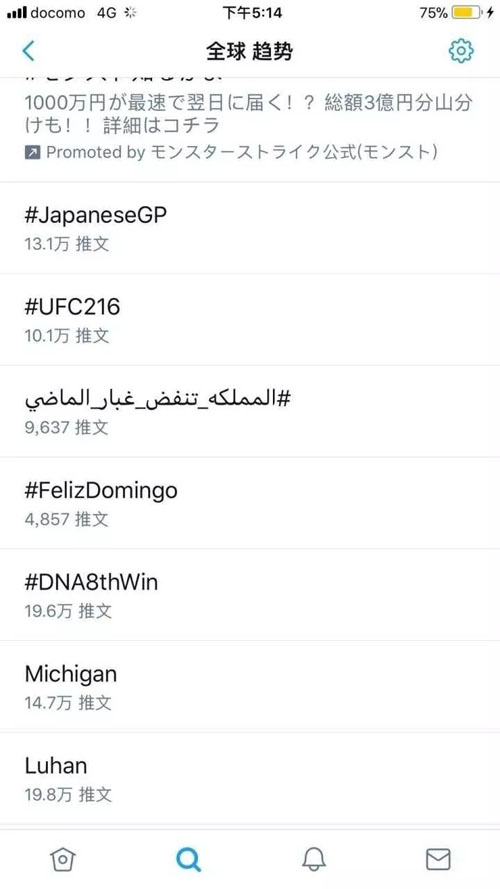
全球的女鹿饭们一起失恋了。
那么鹿晗的粉丝们情绪如何呢?我们来分析一下鹿晗恋情微博的评论,分析评论时粉丝们的心情状态,且听我娓娓道来。(想看分析结果的可直接跳到第 5 节)
新浪微博 API
在经历了几次爬虫被禁的悲痛(真的很痛)之后,我学会了在爬网站之前先查有没有 API 的“优良”习惯。
新浪作为一个大厂,怎么会不推出新浪微博 API 呢,面向开发者新浪有自己的开放平台,这里是 Python 调用微博 API 的方法,通过登录 App_key 和 App_secret 方式访问微博 API 的代码,代码是基于 PY2 的。PY3 对 Weibo 模块使用存在一定问题。
- from weibo import APIClient
- import webbrowser
- import sys
- reload(sys)
- sys.setdefaultencoding('utf-8')
- APP_KEY = '你的App Key ' #获取的App Key
- APP_SECRET = '你的AppSecret' #获取的AppSecret
- CALLBACK_URL = 'https://api.weibo.com/oauth2/default.html' #回调链接
- client = APIClient(app_key=APP_KEY, app_secret=APP_SECRET, redirect_uri=CALLBACK_URL)
- url = client.get_authorize_url()
- webbrowser.open_new(url) #打开默认浏览器获取code参数
- print '输入url中code后面的内容后按回车键:'
- code = raw_input()
- r = client.request_access_token(code)
- access_token = r.access_token
- expires_in = r.expires_in
- client.set_access_token(access_token, expires_in)
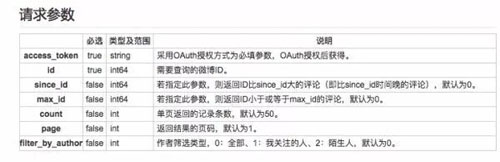
知道如何登录 API 了,辣么如何调用 API 爬单条微博的评论呢?一行代码搞定。
- r = client.comments.show.get(id = 4160547165300149,count = 200,page = 1)
所有关于单条微博的评论信息都在 r.comments 中了,这里需要对照微博 API 文档,微博 API 有声明调用微博评论 API 需要获取用户授权。
但是捏,只要知道单条微博的 id,就可以调用这个 API 了,关于单条微博的 id 如何获取在后面会说(小声一点,千万别让微博知道,万一封了呢)。

按照 client. 接口名 .get(请求参数)的方式获取 API,获取 API 后的规格可在接口详情中查看,文档中有给出返回结果的示例。

文档中也给出了关键数据的 json 接口名称。
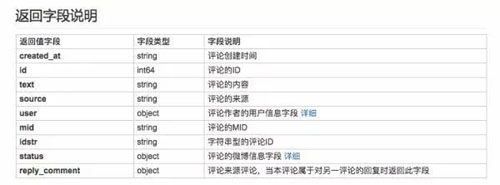
如果我们要获取微博评论的内容,只需要调用 text 接口即可。
- for st in r.comments:
- text = st.text
微博爬虫
通过调用新浪微博 API 的方式,我们就可以简单获取单条微博的评论信息了,为啥说简单呢,因为人红信息贵啊!
你以为大 V 的微博就这么免费的给你 API 调用了吗,非认证应用开发者单日只能请求千次 API,这对像鹿晗这样单条微博几十万评论的大 V 来说…太少了(TT)
所以捏,还是要写微博爬虫。
正所谓,知己知彼百战不殆,新浪作为大厂,怎么说也是身经百战,必定是经历了无数场爬虫与反爬之间的战争,必然有着健全的反爬策略。正所谓,强敌面前,绕道而行,有位大佬说得好,爬网站,先爬移动端:https://m.weibo.cn/
登录微博后,进入到鹿晗公布恋情的微博中去,_(:зゝ∠)_ 已经有 200w+ 评论了,可以看到安静的微博下粉丝们不安的心…
移动端微博的网址显得肥肠简单,不似 PC 端那么复杂而不明逻辑:https://m.weibo.cn/status/4160547165300149
多点几条微博就可以知道 status 后面的数字,就是单条微博的 id 了。
评论里包含了热门评论和***评论两种,但无论是哪种评论,继续往下翻,网址都不会变化。在 chrome 浏览器右键“检查”,观察 Network 变化。
从 Network 的 xhr 文件中,可以得知热门评论的变化规律是:
- 'https://m.weibo.cn/single/rcList?format=cards&id=' + 单条微博id + '&type=comment&hot=1&page=' + 页码
***评论的变化规律是:
'https://m.weibo.cn/api/comments/show?id=' + 单条微博id + '&page=' + 页码
打开
https://m.weibo.cn/single/rcList?format=cards&id=4154417035431509&type=comment&hot=1&page=1 就可以看到热门评论的 json 文件。
接下来就是套路了,伪装浏览器 header,读取 json 文件,遍历每一页…这都不是重点!直接上代码~这里开始是 PY3 的代码了~
- import re,time,requests,urllib.request
- weibo_id = input('输入单条微博ID:')
- # url='https://m.weibo.cn/single/rcList?format=cards&id=' + weibo_id + '&type=comment&hot=1&page={}' #爬热门评论
- url='https://m.weibo.cn/api/comments/show?id=' + weibo_id + '&page={}' #爬时间排序评论
- headers = {
- 'User-agent' : 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.12; rv:55.0) Gecko/20100101 Firefox/55.0',
- 'Host' : 'm.weibo.cn',
- 'Accept' : 'application/json, text/plain, */*',
- 'Accept-Language' : 'zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3',
- 'Accept-Encoding' : 'gzip, deflate, br',
- 'Referer' : 'https://m.weibo.cn/status/' + weibo_id,
- 'Cookie' : '登录cookie信息',
- 'DNT' : '1',
- 'Connection' : 'keep-alive',
- }
- i = 0
- comment_num = 1
- while True:
- # if i==1: #爬热门评论
- # r = requests.get(url = url.format(i),headers = headers)
- # comment_page = r.json()[1]['card_group']
- # else:
- # r = requests.get(url = url.format(i),headers = headers)
- # comment_page = r.json()[0]['card_group']
- r = requests.get(url = url.format(i),headers = headers) #爬时间排序评论
- comment_page = r.json()['data']
- if r.status_code ==200:
- try:
- print('正在读取第 %s 页评论:' % i)
- for j in range(0,len(comment_page)):
- print('第 %s 条评论' % comment_num)
- user = comment_page[j]
- comment_id = user['user']['id']
- print(comment_id)
- user_name = user['user']['screen_name']
- print(user_name)
- created_at = user['created_at']
- print(created_at)
- text = re.sub('<.*?>|回复<.*?>:|[\U00010000-\U0010ffff]|[\uD800-\uDBFF][\uDC00-\uDFFF]','',user['text'])
- print(text)
- likenum = user['like_counts']
- print(likenum)
- source = re.sub('[\U00010000-\U0010ffff]|[\uD800-\uDBFF][\uDC00-\uDFFF]','',user['source'])
- print(source + '\r\n')
- comment_num+=1
- i+=1
- time.sleep(3)
- except:
- i+1
- pass
- else:
- break
这里有四点说明:
- 设置爬取间隔时间之后,微博爬虫被禁的概率降低了很多(特别是晚上)。
- 新浪每次返回的 json 数据条数随机,所以翻页之后会出现数据重复的情况,所以用到了数据去重,这会在后面说。
- 在 text 和 source 中添加了去除 emoji 表情的代码(折腾了很久写不进数据库,差点就从删库到跑路了/(ㄒoㄒ)/),同时也去除了掺杂其中的回复他人的 html 代码。
- 我只写了读取数据,没有写如何保存,因为我们要用到数!据!库!辣!(这是重点!敲黑板)
Python 中数据库的读取与写入
虽然微博爬虫大大提高了数据获取量,但也因为是爬虫而容易被新浪封禁。
这里结束循环的判断是网络状态不是 200,但当微博发现是爬虫时,微博会返回一个网页,网页中什么实质内容都木有,这时候程序就会报错,而之前爬到的数据,就啥也没有了。
但是如果爬一会,保存一次数据,这数据量要一大起来…冷冷的文件在脸上胡乱地拍…我的心就像被…这时候我们就需要用到数据库了。
数据库,顾名思义,就是存放数据的仓库,数据库作为一个发展了 60 多年的管理系统,有着庞大的应用领域和复杂的功能……好了我编不下去了。
在本文中,数据库的主要作用是 AI 式的 excel 表格(●—●)。在爬虫进行的过程中,爬到一个数就存进去,爬到一个数就存进去,即使爬虫程序运行中断,中断前爬到的数据都会存放在数据库中。
大多数数据库都能与 Python 对接使用的,米酱知道的有 MySQL、SQLite、Mongodb、Redis。
这里用的是 MySQL,Mac上 MySQL 的安装,管理数据库的软件 Navicat 使用帮助,其他系统自己找吧,安装使用过程中有啥问题,请不要来找我(逃
根据上面的代码,在 navicat 中创建数据库、表和域以及域的格式。在 Python 程序中添加代码。
- conn =pymysql.connect(host='服务器IP(默认是127.0.0.1)',user='服务器名(默认是root)',password='服务器密码',charset="utf8",use_unicode = False) #连接服务器
- cur = conn.cursor()
- sql = "insert into nlp.love_lu(comment_id,user_name,created_at,text,likenum,source) values(%s,%s,%s,%s,%s,%s)" #格式是:数据名.表名(域名)
- param = (comment_id,user_name,created_at,text,likenum,source)
- try:
- A = cur.execute(sql,param)
- conn.commit()
- except Exception as e:
- print(e)
- conn.rollback()
运行 Python 程序,大概爬了 1w 条实时评论,在进行下一步研究之前,我们还要将数据库中的内容读取出来,Python 中数据库的读取代码也很简单。
- conn =pymysql.connect(host='服务器IP',user='用户名',password='密码',charset="utf8") #连接服务器
- with conn:
- cur = conn.cursor()
- cur.execute("SELECT * FROM nlp.love_lu WHERE id < '%d'" % 10000)
- rows = cur.fetchall()
这样之前爬取的信息就被读取出来了,但是前面也说了,微博爬虫翻页时返回数据条数随机,所以会出现重复的状况,所以读取之后,需要用 if…not in 语句进行一个数据去重。
- for row in rows:
- row = list(row)
- del row[0]
- if row not in commentlist:
- commentlist.append([row[0],row[1],row[2],row[3],row[4],row[5]])
完整代码在文末。
自然语言处理 NLP
NLP 是人工智能的一个领域,可以通过算法的设计让机器理解人类语言,自然语言也属于人工智能中较为困难的一环。
像中文这么博大精深、变幻莫测的语言更是 NLP 中的一大难点,Python 中有很多 NLP 相关的模块,有兴趣的盆友可以通过用 Python 实现简单的文本情感分析初探 NLP。
我参(ban)考(yun)了一些现成的情感分析算法,对爬取的评论进行分析,错误率肥肠高_(:зゝ∠)_ ,这可肿么办?难道要重新设计算法?我仿佛遇到了人生中***个因为语文没学好而引发的重大问题……
当然像我这样灵(lan)活(duo)的姑娘,自然是很快发现了 Python 中较为出名的一个中文 NLP 库:snowNLP。snowNLP 调用的方法比较简单,源码中详细解释了调用方法和生成结果。
- def snowanalysis(textlist):
- sentimentslist = []
- for li in textlist:
- s = SnowNLP(li)
- print(li)
- print(s.sentiments)
- sentimentslist.append(s.sentiments)
这段代码中获取了读取数据库后由评论主体 text 生成的列表文件,并依次对每一个评论进行情感值分析。
snowNLP 能够根据给出的句子生成一个 0-1 之间的值,当值大于 0.5 时代表句子的情感极性偏向积极,当分值小于 0.5 时,情感极性偏向消极,当然越偏向俩头,情绪越明显咯,让我们来看看测试评论的结果。

可以从文字内容和下面对应的数值看出,祝福或者表现的积极的情绪,分值大多高于 0.5,而期盼分手或者表达消极情绪的分值,大多低于 0.5。分析结果中也存在一定的误差,可以通过训练对算法进行优化,米酱语文不好就不瞎搞了…(逃
分析结果
让我们来看看本次分析的结果(●—●)。
- plt.hist(sentimentslist,bins=np.arange(0,1,0.02))
- plt.show()
对上节经过处理得到的情感值列表进行统计,并生成分布图。下图数据采集时间 10 月 9 日 19 时,采集评论 1w 条。
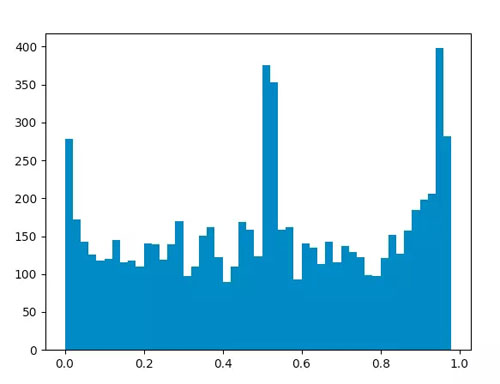
↑鹿晗宣布恋爱微博评论情感值分布
再看看关晓彤回应的微博情况。
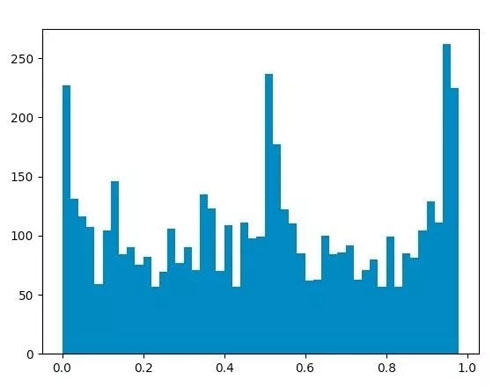
↑关晓彤对应微博评论情感值分布
根据这两张图,可以看到情感值在接近 0、1 两端以及 0.5 左右位置频率较高,说明粉丝们对于此类事件的情绪无论是积极还是消极都是比较明显的。但也可以看出,积极的情绪更多于消极的情绪。
我又对评论中出现的微博表情进行了统计。

给鹿晗的评论中表情的数量是关晓彤的近 3 倍,而排在***位的,都是 [加油],可以看到粉丝们对鹿晗的恋情还是支持居多的,当然也不乏有些人想要 [bm投诉] 主角们了,也有部分人感到 [悲伤],想要冷静一下 [别烦我]。
再对评论内容进行一下词云分析。

↑鹿晗宣布恋爱微博评论词云

↑关晓彤对应微博评论词云
在鹿晗的微博下面出现了大量的祝福、支持、一起等词汇,也有一些为什么、不配、分手之类质疑的声音;在关晓彤的微博下面也存在相同的词汇,但是好像还有大量的关于热巴、李易峰的字眼,看来两位都有绯闻 CP 呀。
你们猜词云的背景图是什么?我就不说了,你们自己感受。
参考资料:
1.微博开放平台:http://open.weibo.com/
2.Python调用微博API的方法:http://blog.csdn.net/gamer_gyt/article/details/51839159
3.微博API文档:http://open.weibo.com/wiki/%E5%BE%AE%E5%8D%9AAPI
4.MySQL的安装:http://www.jianshu.com/p/2d902dd4fff4
5.Navicat使用帮助:http://www.jianshu.com/p/326c1aaa1052
6.if…not in语句:http://www.cnblogs.com/ranjiewen/p/6305684.html
7.用Python实现简单的文本情感分析:https://zhuanlan.zhihu.com/p/23225934
8.snowNLP:https://github.com/isnowfy/snownlp